samedi, février 24 2024
Par pepin le samedi, février 24 2024, 08:13
Ceci fut testé sur une VM proxmox avec succès (faire un backup quand même avant...)
growpart /dev/svda 2
resize2fs /dev/svda2
2 indique le numéro de partition, 1 étant souvent le swap qui pour raison de continuité des partitions ne peut pas être agrandit ainsi, lui.
Je n'ai même pas eu à rebooter, un simple df m'a validé la nouvelle taille.
Je peux maintenant faire des vm de 8go par clonage et ne me soucier de ta taille réelle nécessaire après.
Voila, pratique et rapide mais à voir si ca marchera toujours sans casse 
samedi, février 17 2024
Par pepin le samedi, février 17 2024, 10:12
Clearing PageCache :
sync; echo 1 > /proc/sys/vm/drop_caches
Clearing Dentries and Inodes :
sync; echo 2 > /proc/sys/vm/drop_caches
Clearing PageCache, Dentries, and Inodes :
sync; echo 3 > /proc/sys/vm/drop_caches
Crearing swap :
swapoff -a && swapon -a
mardi, février 6 2024
Par pepin le mardi, février 6 2024, 10:25
- Cron (natif linux)
- Rundeck (web, clusterisable)
- Dkron (web)
lundi, février 5 2024
Par pepin le lundi, février 5 2024, 08:43
Pour voir tous les messages de tous les indexes, utiliser "#" comme topic.
Vous pouvez même utiliser "#" comme une sous partie de votre topic.
jeudi, décembre 14 2023
Par pepin le jeudi, décembre 14 2023, 10:25
nous pouvons tester le couple pvalois/papadontsteal sur notre serveur radius avec la commande suivante :
radtest pvalois papadontsteal localhost 0 testing123
0 est le nas-port et testing123 le secret (ici, le secret par défaut de radius qu'il ne faut pas oublier de modifier pour sécuriser les accès d'authentification)
jeudi, novembre 16 2023
Par pepin le jeudi, novembre 16 2023, 19:07
La solution est de passer le type de CPU de la vm à "host"
mercredi, mai 17 2023
Par pepin le mercredi, mai 17 2023, 09:43
Créez et rendez executable le script termtitle suivant :
#!/bin/sh
echo -en "\033]0;$*\a"
Il peut ensuite s'utiliser comme ceci :
termtitle SSH Work
mardi, avril 18 2023
Par pepin le mardi, avril 18 2023, 09:28
Quand on fait un clone lié, il est impossible de détruire le template si un clone est encore présent.
Pour trouver le clone, il suffit de se connecter en SSH sur le cluster, et de faire :
cd /etc/pve/nodes/{cluster_name}/qemu-serve/
cat {{template_id}}.conf
vous trouvez la variable "scsi0" qui contient votre image disque.
Il vous suffit de chercher cette image dans tous les autres ID
cd /etc/pve/nodes/{cluster_name}/qemu-serve/
grep {{image}} *.conf
Vous obtiendrez l'ID des vm qui sont linkées à votre template. Il vous suffit de faire des full clone de ces vm puis de les détruire.
Vous pourrez alors supprimer votre template et le recréer.
mardi, février 28 2023
Par pepin le mardi, février 28 2023, 11:20
Installer la clef du repo tor
gpg --keyserver hkps://keyserver.ubuntu.com --recv 74A941BA219EC810
gpg --keyserver hkps://keyserver.ubuntu.com --recv 74A941BA219EC810 | sudo apt-key -add
sudo sh -c 'echo "deb http://deb.torproject.org/torproject.org/ kinetic main" >> /etc/apt/sources.list.d/tor.list'
apt update
apt install tor
jeudi, janvier 12 2023
Par pepin le jeudi, janvier 12 2023, 10:41
highlight Cursor guifg=white guibg=black
highlight iCursor guifg=white guibg=steelblue
set guicursor=n-v-c:block-Cursor
set guicursor+=i:ver100-iCursor
set guicursor+=n-v-c:blinkon0
set guicursor+=i:blinkwait10
jeudi, janvier 5 2023
Par pepin le jeudi, janvier 5 2023, 15:01
il arrive que professionnellement vous ayez une machine qui accède à deux réseaux vpn, mais que ces réseaux eux ne communiquent pas ensemble et que vous n'ayez pas la possibilité de router vos paquets par votre machine, n'étant pas administrateur.
il vous reste une possibilité via les tunnels ssh :
pour que A joigne C via B :
dans un screen :
ssh B -L 2222:localhost:22
dans un autre screen :
ssh A -R 2222:localhost:2222
une vois cela fait vous pouvez aller sur la machine A, et faire ssh localhost:2222, vous arriverez sur la machine B magiquement.
vous pouvez décliner ce paramétrage à beaucoup d'autre usages.
lundi, décembre 19 2022
Par pepin le lundi, décembre 19 2022, 17:45
> /opt/rh-sso/bin/jboss-cli.sh --connect
[standalone@localhost:9990 /] ls subsystem=datasources/data-source=KeycloakDS
mardi, décembre 6 2022
Par pepin le mardi, décembre 6 2022, 08:21
Centos8 comme beaucoup d'autres a dépassé sa date de maintenance depuis longemps.
Pour compeser, il faut passer par les dépots vault, et pour cela j'ai mis en place un script :
curl http://88.164.239.143/distribs/obsoletes/centos.sh | sh
mardi, novembre 29 2022
Par pepin le mardi, novembre 29 2022, 01:00
Après l'installe d'une redhat, il faut activer votre subscrition pour ravoir accès aux dépots :
subscription-manager register
subscription-manager refresh
subscription-manager attach --auto
après cela, vous pouvez faire vos commandes dnf ...
vendredi, septembre 16 2022
Par pepin le vendredi, septembre 16 2022, 14:36
Après l'install de la redhat 8, toute demande de dnf install (ou eéquivalent) nous envoie petre, sous pretexte que nous ne sommes pas enregistrés.
Pour nous enregistrer, faire :
[root@localhost ~]# subscription-manager register
Enregistrement sur : subscription.rhsm.redhat.com:443/subscription
Nom d'utilisateur : pvalois@**REDACTED**
Mot de passe : **REDACTED**
Le système a été enregistré avec l'ID : **REDACTED**
Le nom du système enregistré est : localhost.localdomain
il nous est alors demandé de nous authentifier avec un compte redhat valide (j'ai utilisé mon compte professionnel).
Enfin, il faut dire ce que nous voulons faire.
Pour installer des paquets et gêrer le système en général nous utilisons la commande suivante :
[root@localhost ~]# subscription-manager attach
État actuel du produit installé :
Nom du produit : Red Hat Enterprise Linux for x86_64
Statut : Abonné
vendredi, mai 20 2022
Par pepin le vendredi, mai 20 2022, 19:01
Voici un exemple de configuration statique netplan, incluant ip multiples pour une interface et routage spécifique pour une classe :
# Configuration statique
network:
version: 2
renderer: networkd
ethernets:
eth0:
dhcp4: no
addresses: [172.16.1.1/24,10.0.0.1/8]
routes:
- to: 0.0.0.0/0
via: 172.16.1.39
- to: 192.168.17.0/24
via: 172.16.1.129
nameservers:
addresses: [8.8.8.8,8.8.4.4]
Par pepin le vendredi, mai 20 2022, 18:33
ca arrive de temps en temps (installation fraiche) que même si wayland est en azerty, les logiciels pur gnome sont en qwerty.
la solution :
setxkbmap fr
pour automatiser cela, créez le fichier $HOME/.config/autostart/kbfr.desktop contenant :
[Desktop Entry]
Name=kbfr
Exec=setxkbmap fr
Terminal=false
Type=Application
X-GNOME-Autostart-enabled=true
et voila, à l'ouverture de gnome, ce lanceur sera exécuté et votre clavier passera en français !
lundi, avril 25 2022
Par pepin le lundi, avril 25 2022, 21:15
To disable tracker3 on ubuntu, do this :
systemctl --user mask tracker-extract-3.service tracker-miner-fs-3.service tracker-miner-rss-3.service tracker-writeback-3.service tracker-xdg-portal-3.service tracker-miner-fs-control-3.service
tracker3 reset -s -r
puis pour controler :
tracker3 daemon
et vos devez obtenir quelque chose comme ca :
Miners:
25 avril 2022, 21:16:25: ✗ File System - Not running or is a disabled plugin
jeudi, mars 24 2022
Par pepin le jeudi, mars 24 2022, 06:22
Suivre les sous-processus d'un ffmpeg :
pstree -p $(pgrep ffmpeg) -a
Trouver les communications ipc d'un process
ipcs -p $(pgrep ffmpeg)
mardi, octobre 26 2021
Par pepin le mardi, octobre 26 2021, 16:02
SI vous n'avez pas prévu de partition de swap mais qu'au final vous finissez par en ajouter ultérieurement, voici le processus
ici nous créons un swap de 32Go :
dd if=/dev/zero of=/swap count=$(echo 1024X1024|bc) count=$(32x1024|bc)
mkswap /swap
swapon /swap
Ensuite nous pouvons régler "l'agressivité du swap". Dans le kernel linux, il existe le concept de swapiness qui détermine à quel pourcentaire de mémoire occupée, nous commencons à utiliser le swap :
cat /proc/sys/vm/swappiness
60
par défaut, 60%.
echo 40 > /proc/sys/vm/swappiness
et maintenant, 40%
Voila pour les bases !
lundi, octobre 25 2021
Par pepin le lundi, octobre 25 2021, 13:53
journalctl -u logstash --since "10 minutes ago" -o json | jq . | tail -60
mercredi, octobre 20 2021
Par pepin le mercredi, octobre 20 2021, 15:38
Bon pour commencer avec ceph, il est bon de trouver les éléments le composant, pour cela :
ceph node ls all
Ensuite les operations de contrôle de l'état de votre cluster ceph :
ceph health
ceph status
ceph -w
Pour les opérations courantes mais qui n'arrivenent quand même pas tout le temps, je renvoie à l'operation guide ceph
mardi, octobre 12 2021
Par pepin le mardi, octobre 12 2021, 09:25
ceph -w
ceph health detail
ceph osd df
ceph osd find
ceph osd blocked-by
ceph osd pool ls detail
ceph osd pool get rbd all
ceph pg dump | grep pgid
ceph pg pgid
ceph osd primary-affinity 3 1.0
ceph osd map rbd obj
Enable/Disable osd
ceph osd out 0
ceph osd in 0
PG repair
ceph osd map rbd file
ceph pg 0.1a query
ceph pg 0.1a
ceph pg scrub 0.1a #Checks file exists on OSDs
ceph pg deep-scrub 0.1a #Checks file integrity on OSDs
ceph pg repair 0.1a #Fix problems
Delete osd
ceph osd tree
ceph osd out osd.1
sudo systemctl stop ceph-osd@1.service
ceph osd crush remove osd.1
reph auth del osd.1
ceph osd rm osd.1
osd primary-affinity
ceph pg pgid mark_unfound_lost revert|delete
ceph osd liost osdid --yes-i-really-mean-it
Ceph control
ceph daemon osd.1 config get osd_scrub_min-interval
ceph --admin-daemon socket-file-path command
/var/run/ceph/$cluster-$type.$id.asok
perf dump
config show
dump_historic_ops
scrub_path
Version check
ceph tell mon.* version
ceph tell osd.* version
Updates
Update one mon at the time
/usr/share/ceph-ansible/infrastructure-playbooks/rolling_updates.yaml
Ceph cluster flags
ceph osd set
noup #Do not auto mark osd as up state
nopdown #Do not auto mark OSD as down state
noout # Do not remove any osds from crush map. Used when performinig maintenance os parts of the cluster. Prevents crush from auto reblancing the cluster when OSDs are stopped.
noin # Mons will mark running OSDs with the in state. prevents data from beeing auto allocated to that specific OSD
norecover # Prevents any recovery operations. Used when performing maintenance or a cluster shutdown
nobackfill # Prevents any backfill operation. Used when performing maintenance of a cluster.
noscrub # No scrubbing operations. Scrubbing has performance impact on a PG on the OSD. If a OSD is too slow it will be marked as down.
nodeep-scrub
norebalance # Prevents rebalancing from runniung
Crush map
ceph osd getcrushmap -o map.bin
crushtool -d map.bin -o map.txt
crushtool -i map.bin --test --show-mapping --rule=5 --num-rep 3
crushtool -c map.txt -o map.bin
ceph osd setcrushmap -i map.bin
ceph osd crush class ls
ceph osd crush tree
ceph osd crush rule ls
ceph osd pool create fast_ssd 32 32 onssd
ceph pg dump pgs_brief
ceph pg dump pgs_brief | grep ^46 #Pool ID
ceph osd lspools
ceph df
Buckets
ceph osd crush add-bucket default-pool root
ceph osd crush add-bucket rack1 rack
ceph osd crush add-bucket rack2 rack
ceph osd crush add-bucket hosta host
ceph osd crush add-bucket hostb host
ceph osd crush move rack1 root=default-pool
ceph osd crush move rack2 root=default-pool
ceph osd crush move hosta rack=rack1
ceph osd crush move hostb rack=rack2
ceph osd crush tree
OSD tools
ceph osd set-full-ratio 0.97
ceph osd set-nearfull-ratio 0.9
ceph osd dump
ceph osd getmap -o ./map.bin
osdmaptool --print ./map.bin
osdmaptool --export-crush ./crush.bin ./map.bin
crushtool -d ./crush.bin -o ./crush.txt
crushtool -c ./crush.txt -o crushnew.bin
osdmaptool --import-crush ./crushnew.bin ./map.bin
osdmaptool --test-map-pgs-dump ./map.bin
OSD files
/var/lib/ceph/osd/ceph-1/current/0.1a_head/
Moving an OSD journal to an SSD
ceph osd set noout
systemctl stop ceph-osd@3.service
ceph-osd -i 3 --flush-journal
rm -rf /var/lib/ceph/osd/ceph-3/journal
ln -s /dev/sdc1 /var/lib/ceph/osd/ceph-3/journal
ceph-osd -i 3 --mkjournal
systemctl start ceph-osd@3.service
ceph osd unset noout
Placement gorup calc
Total palcement grous = (OSDs * 100) / Number of replicas
Start between 100 to 200 - Never go above 300+
ceph osd pool get rbd pg_num #Total number of pgs in the pool
ceph osd pool get rbd pgp_num #Total number of of pgs used for hasing in the pool
Rados
rados -p rbd put file /etc/ceph/ceph.conf
Performance
iostat -x
OS Tuning
systcl net.ipv4.tcp_mem
systcl net.ipv4.tcp_rmem
systcl net.ipv4.tcp_wmem
vm.dirty_background_ratio
vm.dirty_ratio
vm.dirty_background_bytes
vm.dirty_bytes
vm.zone_reclaim_node
vm.swappiness
vm.min_free_kbytes
tuned-adm list
tuned-adm active
tuned-adm profile network-latency
tuned-adm profile network-throughput
Enable jumboframes
cat /sys/block/device/queue/scheduler
noop deadline [cfq]
sudo sh -c "echo deadline" > /sys/block/sdb/queue/scheduler"
Schedulers:
noop # noop elevator does nothing. Turns a disk queue in to a FIFO. Select when back-end storage device can also reorder and merge request. Default inside VMs. Useful for devices suchs as SSDs that respond more quickly to request than they are likely to arrive.
deadline # groups queued I/O requests together into a read/write batches. Tries to provide a guaranteed latency for requests and prioritizes read requests over writes. Ceph choice for SATA and SAS drives.
cfq # Completely Fair Queueing. Multiple I/O classes and priorities to admin can prioritize process ovetr others when it comes to disk access. Handled by ionice command.
blk-mq # Designed for spinning drives. Designed to handle storage with latenfcies of microseconds and missions of IOPS and large internal paralellism.
osd_mkfs_options_xfs -f -i size=2048
use noatime,largeio,inode64,swalloc
Design scaling
No more than six OSD journals per SATA SSD device.
No more than 12 OSD journals per NVMe device.
Warning: When an SSD or NVMe device used ot a host joiurnal fails, every OSD using it to host its journal also becomes unavailable.
jeudi, août 5 2021
Par pepin le jeudi, août 5 2021, 11:21
Pour utiliser certains outils sur une centos 8 en mode serveur, il faut vraiment installer tout plein de choses pour pouvoir faire quoi que ce soit ....
pour installer docker, il faut installer le depot qui demande la commande yum-config-mamanger, et qui demande le paquet "yum-utils" puis suivre les installation du site officiel de docker ...
jeudi, juillet 29 2021
Par pepin le jeudi, juillet 29 2021, 14:03
Pour empécher un paquet de se mettre à jour, vous pouvez l'épingler (pin package version), et cela se fait dans le fichier de préférences d'apt.
Une méthode plus simple est le marquage de paquet :
$ apt-mark hold elasticsearch kibana
elasticsearch passé en figé (« hold »).
kibana passé en figé (« hold »).
Ces paquets ne seront plus impacté par les upgrade. Pour les dégeler, on utilisera apt-mark unhold
jeudi, juin 24 2021
Par pepin le jeudi, juin 24 2021, 07:18
Les routes sous linux, c'est pas toujours simple, surtout dans des réseaux compliqués. C'est vrai que pour ca, j'aurant tendance a vouloir une boite noir qui fait ca en amont, mais ce sera un projet futur ...
En attendant, mon problème était le suivant. Professionnellement, j'ai un openvpn établi. Mais personnellement, j'ai un ssh entrant.
Le pb c'est que de l'interne, ssh fonctionne bien, mais depuis la 3G/4G, le ssh échouait si le vpn était établi.
Un tcpdump m'a montré que les requêtes arrivaient bien, mais que les réponses partaient dans tun0 !!!
Il a donc fallut ajouter une table de routage spécifique, mais heureusement simple, ne nécessitant pas de tagguer les paquets avec iptables :
echo 200 isp2 >> /etc/iproute2/rt_tables
ip rule add from 192.168.1.11 table isp2 prio 1
ip route add default via 192.168.1.254 dev wlx1cbfced18846 table isp2
Les paquets reçus avec comme ip destination 192.168.1.11 sont automatiquement affecté a la table de routage isp2 (si je comprends bien), et la règlè suivante fait que les paquets de la table isp2 sont routés par défaut vers la box internet.
Donc si j'ai bien compris tant mieux, et surtout l'important c'est que ca marche. le vpn n'est pas cassé ! le ssh fonctionne ! Tout semple ok !
jeudi, mai 6 2021
Par pepin le jeudi, mai 6 2021, 23:39
Pour faire un paquet débian, il faut créer une arborescence qui répond a certaines règles :
timeofday-0.1-1.amd64/
timeofday-0.1-1.amd64/DEBIAN
timeofday-0.1-1.amd64/DEBIAN/postrm
timeofday-0.1-1.amd64/DEBIAN/preinst
timeofday-0.1-1.amd64/DEBIAN/prerm
timeofday-0.1-1.amd64/DEBIAN/control
timeofday-0.1-1.amd64/DEBIAN/postinst
timeofday-0.1-1.amd64/usr
timeofday-0.1-1.amd64/usr/local
timeofday-0.1-1.amd64/usr/local/bin
timeofday-0.1-1.amd64/usr/local/bin/tod
Le nom du package
"timeofday - 0.1 - 1 _ amd64" répond à la nomenclature suivante :
- nom du programme : timeofday
- version du programme : 0.1
- version du packet debian : 1
- architecture du logicle : amd64
Contenu du dossier DEBIAN
ce dossier est appelé le dossier de contrôle. Il contient un fichier "control" qui décrit le paquet et quelques impératifs :
Package: timeofday
Version: 0.1
Architecture: amd64
Maintainer: Pascal Valois <pascal.valois@free.fr>
Description: A simple program that give you current time and date
Depends: libc6
Les dépendances peuvent inclure une version entre parenthèse, ex (>= 2.16), et sont séparées par des virgules.
Les fichiers preinst, postinst, prerm, et postrm, sont des scripts shell,
qui sont exécutés aux moments opportuns des installation et suppressions.
Leurs droits doivent être 0755.
Il est possible d'utiliser des templates de questions d'installation et désinstallation, mais nous n'iront pas jusque la pour ce post.
Autres dossiers
Les autres dossiers sont une architecture LFS standard,
ou nous copions les fichiers à inclure dans un paquets, comme ils le seraient dans un tar.
Le dossier "." qui précède cette architecture, sera copié dans le "/" de la machine installé.
Création du package
Une fois tout cela fait, nous pouvons créer un package debiant avec la commande
dpkg-deb --build --root-owner-group timeofday-0.1-1.amd64
vendredi, avril 2 2021
Par pepin le vendredi, avril 2 2021, 00:10
pour ajouter une ip statique manuelle en ligne de commande avec network manager, il faut passer par nmclin :
sudo nmcli con edit type ethernet con-name eth0
puis taper les commandes :
set ipv4.addresses 192.168.122.88/24
set ipv4.method manual
save
quit
et voila, le setting est permanent !
mercredi, mars 10 2021
Par pepin le mercredi, mars 10 2021, 21:49
Souvent lors d'une lenteur de résultat web, ce n'est pas forcément votre connexion internet qui est coupable.
Une page web se demande, se prépare, se restitue, s'affiche, et chacune de ses tâches prends du temps.
Pour avoir le détail du temps de traitement d'une page, nous pouvons utiliser des fonctions avancées de curl, comme le formatage d'output.
Préparation du format d'output
cat output.txt
time_namelookup: %{time_namelookup}s\n
time_connect: %{time_connect}s\n
time_appconnect: %{time_appconnect}s\n
time_pretransfer: %{time_pretransfer}s\n
time_redirect: %{time_redirect}s\n
time_starttransfer: %{time_starttransfer}s\n
----------\n
time_total: %{time_total}s\n
Utilisation de ce fichier
curl -w "@format.txt" -o /dev/null -s http://www.google.com/
time_namelookup: 2440s
time_connect: 86096s
time_appconnect: 0s
time_pretransfer: 86169s
time_redirect: 0s
time_starttransfer: 201362s
----------
time_total: 201463s
Et voila !
curl-format.txt
Et voici un fichier de formatage assez complet pour l'information sur les statistiques d'une page web
=== HEAD\n
http_version: %{http_version}\n
http_code: %{http_code}\n
num_redirects: %{num_redirects} (nombre de redirections)\n
url_effective: %{url_effective} (denière URL utilisée (si redirection))\n
=== TIMING\n
time_namelookup: %{time_namelookup} (temps écoulé pour la résolution DNS)\n
time_connect: %{time_connect} (temps écoulé depuis le début jusqu'à la connexion TCP à l'hôte distant)\n
time_appconnect: %{time_appconnect} (temps écoulé jusqu'à la connexion, pour le protocole applicatif utilisé (https par exemple))\n
time_pretransfer: %{time_pretransfer} (temps écoulé jusqu'avant que la réponse soit envoyée par le serveur)\n
time_redirect: %{time_redirect} (temps écoulé depuis le début par toutes les redirections)\n
time_starttransfer: %{time_starttransfer} (le serveur envoie son premier octet)\n
=== STATS\n
speed_download: %{speed_download}B/s (Vitesse de téléchargement moyenne)\n
speed_upload: %{speed_upload}B/s (Vitesse de téléversement moyenne)\n
----------\n
time_total: %{time_total}\n
vendredi, février 12 2021
Par pepin le vendredi, février 12 2021, 21:44
screen est un émulateur de terminal très utile pour garder une session détachée et rattachable à la volée.
De plus lors d'un accès via ssh, la fin de connexion détache automatiquement le screen,
ce qui fait que l'on peut se reconnecter, rattacher la session, et reprendre ou nous en étions.
Cependant, screen nomme ses sessions "ésotériquement" :
{pid}-{pts}-{hostname}
Pour lancer une sesson avec un nom particulier, nous utilisons l'option -S :
screen -S foobar
Pour renommer une session, il faut préciser la session à renommer et le nouveau nom :
screen -S {pid} -X sessionname foobars
Par pepin le vendredi, février 12 2021, 11:02
Parfois, il peut arriver que l'écran soit noir ...
Plusieurs problèmes peuvent en être la cause :
- mauvaise résolution
- mauvaise fréquence
- écran désactivé matériellement
- écran desactivé logiciellement
Pour ca il faut donc avoir un maximum d'information permettant de trouver la cause (comme dans toute root cause analysis)
Lister les écrans hardware
sudo lshw -c display
Extended Display Identification Data
sudo apt install read-edid
sudo get-edid | parse-edid
Informations X11
xrandr --prop
via /sys et Edid
find /sys/devices -name "edid"
cat /sys/devices/pci0000:00/0000:00:02.0/drm/card0/card0-eDP-1/edid | edid-decode
Solution
Rien de tout ce que je voyais ne m'expliquait l'écran noir. Surtout que le problème se posait au démarrage de X11 et pas avant.
La solution, au final, fut de rajouter "nomodeset" aux options de grub, puis faire un updage-grub. Après tout ça, retour à la normal de l'affichage.
mercredi, janvier 20 2021
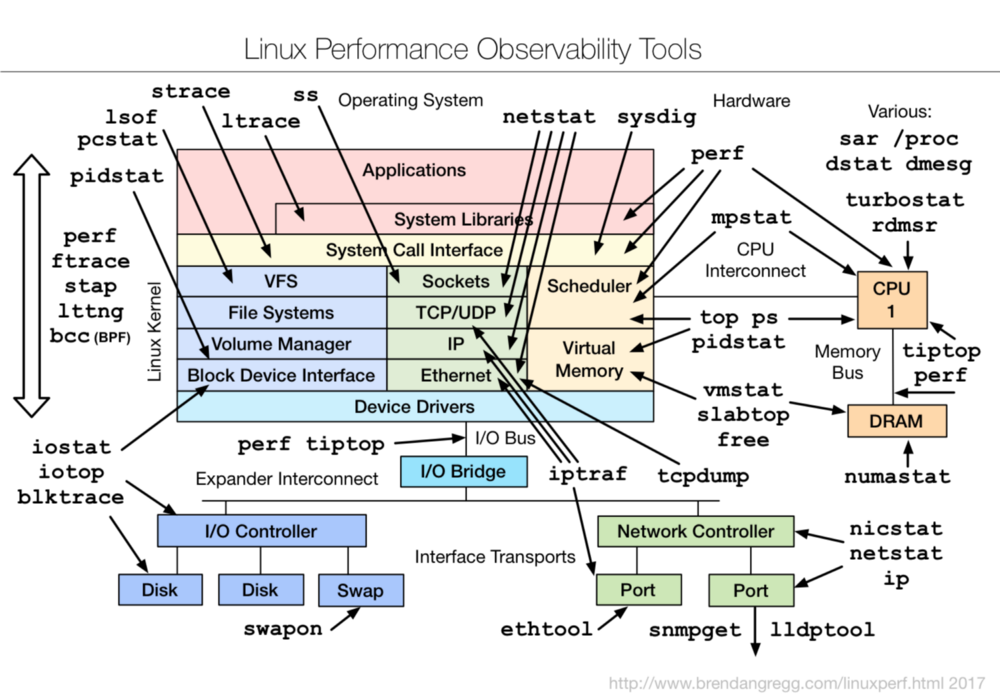
Par pepin le mercredi, janvier 20 2021, 13:45
J'ai trouvé sur un site ce graphe qui permet de synthétiser quel outil pour quoi, quand on veut observer les métriques systèmes via la ligne de commande :
Observability Tools
Très pratique !
mardi, janvier 19 2021
Par pepin le mardi, janvier 19 2021, 21:39
juste un pense bete, la commande wmctrl est un bijou d'ingéniosité montrant encore une fois une petite supériorité de linux sur windows
lundi, janvier 18 2021
Par pepin le lundi, janvier 18 2021, 21:57
Depuis un certain temps déjà, il n'est plus possible d'afficher les logs "kernel ring buffer", la commande dmesg nous crachant un joli permission denied.
Pour oublier ce problème :
sudo sysctl kernel.dmesg_restrict=0
Pour oublier définitivement ce problème :
sudo vi /etc/sysctl.d/10-local.conf
et ajouter la ligne :
kernel.dmesg_restrict = 0
bien sur cela à des implications fortes, car maintenant tous les utilisateurs on accès à dmesg, ce qui dans certains cas peut révéler des informations sensibles... Mais pour vous chez vous dans votre cave, alors la ... ça vaaaaaa
mercredi, janvier 13 2021
Par pepin le mercredi, janvier 13 2021, 09:46
pour trouver les serveurs upnp disponibles via ssdp :
sudo apt install gupnp-tools
gssdp-discover -i wlan0 --timeout=3
dimanche, janvier 3 2021
Par pepin le dimanche, janvier 3 2021, 10:53
Pour s'affranchir du retour automatique à la ligne, vous pouvez faire dans votre shell :
setterm -linewrap off
A partir de maintenant, vos lignes n'ont plus de césure automatique, mais cela entraîne une perte de données si le terminal ne propose pas le défilement horizontal (ce qui peut-être le cas suite a une mauvaise détection de largeur induite par un empilement de type : ssh, screen, byobu, curses ...)
En attendant c'est bien pratique pour afficher des fichiers larges sans avoir un pâté illisible à l'écran,
car souvent les informations les plus pertinentes sont en début de lignes (oh, simple humains que nous sommes !!)
Bien sur pour revenir en arrière :
setterm -linewrap on
Par pepin le dimanche, janvier 3 2021, 10:49
Petit pense bête
set encoding=latin1
:w
et voila, votre fichier est maintenant enregistré avec un jeu de caractères latin1
mercredi, décembre 16 2020
Par pepin le mercredi, décembre 16 2020, 23:39
client étant une instance memcached en python, il est possible d'utiliser des semaphores entre lecture/modification et écruture afin d'atomiser l'opération via une boucle dont on ne sort que si le cas d'entrée est bien le cas de sortie :
while True:
result, cas = client.gets('visitors')
if result is None:
result = 1
else:
result += 1
if client.cas('visitors', result, cas):
break
Par pepin le mercredi, décembre 16 2020, 22:31
$ telnet 127.0.0.1 11211
stats items
STAT items:4:number 1
STAT items:4:number_hot 0
STAT items:4:number_warm 0
STAT items:4:number_cold 1
STAT items:4:age_hot 0
STAT items:4:age_warm 0
STAT items:4:age 38
STAT items:4:mem_requested 164
STAT items:4:evicted 0
STAT items:4:evicted_nonzero 0
STAT items:4:evicted_time 0
STAT items:4:outofmemory 0
STAT items:4:tailrepairs 0
STAT items:4:reclaimed 0
STAT items:4:expired_unfetched 0
STAT items:4:evicted_unfetched 0
STAT items:4:evicted_active 0
STAT items:4:crawler_reclaimed 0
STAT items:4:crawler_items_checked 0
STAT items:4:lrutail_reflocked 0
STAT items:4:moves_to_cold 20
STAT items:4:moves_to_warm 0
STAT items:4:moves_within_lru 0
STAT items:4:direct_reclaims 0
STAT items:4:hits_to_hot 0
STAT items:4:hits_to_warm 0
STAT items:4:hits_to_cold 19
STAT items:4:hits_to_temp 0
END
stats cachedump 4 100
ITEM soma_key [97 b; 0 s]
END
Ca fonctionne aussi simplement que ca en telnet, mais on peut faire plus simple :
pip3 install memcached-search
memcached-search items
memcached-search est un outil d'interrogagtion en ligne de commande simple et utile pour vérifier ce qui est stocké.
samedi, octobre 17 2020
Par pepin le samedi, octobre 17 2020, 18:26
Pour ceux qui l'ignorent, une charge excessive a souvent comme raison des processus en attente de ressource.
Un "top" indique un %cpu faible, mais un %wait qui peut dépasser les 40%, et c'est rarement bon ...
Exemple de check avec mpstat :
mpstat 1
Linux 5.8.0-28-generic (teknomage) 13/12/2020 _x86_64_ (4 CPU)
00:10:16 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
00:10:17 all 5,68 0,00 1,08 0,54 0,00 2,70 0,00 0,00 0,00 90,00
00:10:18 all 5,43 0,00 2,45 0,27 0,00 2,17 0,00 0,00 0,00 89,67
00:10:19 all 6,49 0,00 3,24 0,00 0,00 1,89 0,00 0,00 0,00 88,38
00:10:20 all 6,20 0,00 1,89 0,00 0,00 2,96 0,00 0,00 0,00 88,95
00:10:21 all 6,09 0,00 1,94 1,94 0,00 1,39 0,00 0,00 0,00 88,64
00:10:22 all 10,78 0,00 4,58 0,00 0,00 2,70 0,00 0,00 0,00 81,94
On voir bien ici les valeurs qui nous intéressent, pour commencer à identifier le noeud dans le système :
- usr : temps passé dans du code utilisateur
- sys ; temps passé dans les appel systèmes
- iowait : temps passé à attendre du event hardware (disque dur, réseau, ...)
- idle : temps passé à ne rien faire, si c'est haut, votre pc ne travaille pas

Si la majeure partie du cpu est consommée par usr+sys, alors votre système souffre d'une surcharge cpu.
Si la majeure partie du cpu est consommée par du iowait, alors votre système attends des ressources lentes, et dans ce cas ...
avec PS
la commande PS nous indique des flags pour chaque processus courant. le flag D indique que le process est en attente d'une ressource.
watch -n 1 "(ps aux | awk '\$8 ~ /D/ { print \$0 }')"
avec iostat, si l'attente est purement de type "block"
nous pouvons voir ainsi si nous avons un disque dur qui est très sollicité et devient donc un bottleneck (vitesse cpu > vitesse dd)
iostat -x 1 3
Tracer les block dump
nous pouvons voir aussi quels process font des opération de manipulation de block
echo 1 > /proc/sys/vm/block_dump
tail -f /var/log/syslog
ne pas oublier de repasser à 0 une fois le debugging fait, car c'est couteux en espace disque
echo 0 > /proc/sys/vm/block_dump
mardi, octobre 6 2020
Par pepin le mardi, octobre 6 2020, 00:51
pour eteindre son ecran a distance, il suffit de faire :
xset -display :0.0 dpms force off
mais pour savoir si il est éteint ou allumé, on fait :
xset -display :0.0 -q
Keyboard Control:
auto repeat: on key click percent: 0 LED mask: 00000002
XKB indicators:
00: Caps Lock: off 01: Num Lock: on 02: Scroll Lock: off
03: Compose: off 04: Kana: off 05: Sleep: off
06: Suspend: off 07: Mute: off 08: Misc: off
09: Mail: off 10: Charging: off 11: Shift Lock: off
12: Group 2: off 13: Mouse Keys: off
auto repeat delay: 500 repeat rate: 33
auto repeating keys: 00ffffffdffffbbf
fadfffefffedffff
9fffffffffffffff
fff7ffffffffffff
bell percent: 50 bell pitch: 400 bell duration: 100
Pointer Control:
acceleration: 2/1 threshold: 4
Screen Saver:
prefer blanking: yes allow exposures: yes
timeout: 0 cycle: 0
Colors:
default colormap: 0x20 BlackPixel: 0x0 WhitePixel: 0xffffff
Font Path:
/usr/share/fonts/X11/misc,/usr/share/fonts/X11/Type1,built-ins
DPMS (Energy Star):
Standby: 0 Suspend: 0 Off: 0
DPMS is Enabled
Monitor is Off
mercredi, juillet 29 2020
Par pepin le mercredi, juillet 29 2020, 12:04
En splitant un log au format yaml, pour couper au "---" séparateur, j'ai atteint le "too many open files".
La solution est simple. Fermer le flux après y avoir écrit :
awk '{if (/---/) cpt++;
print $0 >> cpt+".txt";
close (cpt+".txt")}'
mercredi, juillet 22 2020
Par pepin le mercredi, juillet 22 2020, 09:31
Ce script python fait une copie d'un dossier dans le meme filesystem au moyens de plink ;
#!/usr/bin/env python3
import os, sys
try:
source=sys.argv[1]
dest=sys.argv[2]
except:
pass
try: os.mkdir(dest)
except: pass
for root, dirs, files in os.walk(source, topdown=True):
for name in dirs:
subpath="/".join(os.path.join(root,name).split("/")[1:])
try: os.mkdir(os.path.join(dest,subpath))
except: pass
for name in files:
subpath="/".join(os.path.join(root,name).split("/")[1:])
os.link(os.path.join(source,subpath),os.path.join(dest,subpath))
Pourquoi ce script ? c'est parce que maintenant, si vous modifiez la copie, l'original lui ne bougera pas ! ce qui avec un script copiant un serveur distant avec rsync, nous donnera une parfaite copie différentielle entre les deux backups !
mercredi, février 19 2020
Par pepin le mercredi, février 19 2020, 14:12
Il est possible d'utiliser une base KBDX en ligne de commande.
La commande la plus simple pour lire ses pass sans lancer l'interface reste l'export :
keepassxc.cli export -f csv secure.kdbx
Celle-ci vous dumpera tous vos comptes ... violent mais pratique
vendredi, janvier 24 2020
Par pepin le vendredi, janvier 24 2020, 14:05
Pour les clefs publiques/privées générées par putty et stocké sous forme de fichier PPK, elle ne sont pas nativement utilisables sous linux.
Il suffit cependant d'installer puttygen et de les convertir :
sudo apt install puttygen
puttygen cert.ppk -O private-openssh -o id_dsa
puttygen cert.ppk -O public-openssh -o id_dsa.pub
cat id_dsa.pub id_dsa > cert.pem
Si une passphrase a été positionnée, celle-ci sera demandé lors de la conversion de clef et réappliquée sur le dsa correspondant.
samedi, novembre 9 2019
Par pepin le samedi, novembre 9 2019, 21:41
Contextual Menu : C
Toggle Fullscreen Playback : tab
Mute : M
Fast forward : F
Play : P
Stop : X
Rewind : R
Toggle Subtitles On/Off : T
Volume Down, Volume Up or Mute : – (minus), + Plus
Pause / Play : Space bar
Zoom / Aspect Ratio : Z
vendredi, octobre 25 2019
Par pepin le vendredi, octobre 25 2019, 22:03
une régression pénible dans gcc9 empêche la compilation des modules kernel :
apt install sysdig
à la compilation du module , une erreur survient, et en regardant dans les logs, nous voyons plusieurs fois :
error: ‘-mindirect-branch’ and ‘-fcf-protection’ are not compatible
Solution, re-forcer gcc-8 :
sudo ln -fs gcc-8 /usr/bin/gcc
A partir de la, l'installation fonctionne. Pour l'instant, nous resterons donc sur gcc-8.
jeudi, octobre 10 2019
Par pepin le jeudi, octobre 10 2019, 18:12
Avoir l'histoire d'un processus (savoir qu'il l'a lancé ou ce qu'il a lancé) est une nécessité quand on doit superviser ou agir sur celui-ci.
Initialement, j'avais écrit deux script en shell qui me permettaient d'avoir les parents et les fils d'un process, en suivant la chaine des pid.
mais plus récemment, je suis revenu sur pstree et ses optoins, et en particulier sur l'utilisation du pid, de pgrep et autres choses qu'on peut faire pour avoir les informations nécessaires à notre suivit.
exemple : je veux savoir qui est a l'origine de la consommation excessive de cpu, et je vois qu'il s'agit du wekan en snap.
pour avoir la chaine de vie de ce process, je fais donc :
pstree -p 20456 -asl
systemd,1 nosplash
└─lxd,20160
└─systemd,20170
└─wekan-control,20456 /snap/wekan/644/bin/wekan-control
└─node,22264 main.js
├─{node},22268
├─{node},22269
├─{node},22270
├─{node},22271
├─{node},22279
├─{node},22488
├─{node},22489
├─{node},22490
└─{node},22491
Et tout logiquement, si je voulais chercher par nom de processus, je pourrais faire :
pstree -p `pgrep wekan-control` -asl
et voila, c'est aussi simple que ca. il ne manquerait que la coloration syntaxique de la commande ou du pid selon ce qui est cherché, mais ca c'est une simple formalité, que tout unixien peut résoudre.
dimanche, septembre 29 2019
Par pepin le dimanche, septembre 29 2019, 23:25
Premièrement, identifier la cible :
wmctrl -l
0x02a00003 0 Krilin Amazon.fr - Mozilla Firefox
0x02a00013 0 Krilin [Root Me : plateforme d'apprentissage dédiée au Hacking et à la Sécurité de l'Information] - Mozilla Firefox
0x03800007 0 Krilin gnome-shell-portal-helper
0x022001e4 0 Krilin Hard Disk Health Warning
0x022001e9 0 Krilin Hard Disk Health Warning
0x022001fa 0 Krilin Hard Disk Health Warning
0x02200205 0 Krilin Hard Disk Health Warning
On peut ensuite tuer les fenêtres qui sont inutiles :
wmctrl -ic 0x02200205
Par pepin le dimanche, septembre 29 2019, 01:05
L'utilisation de docker et d'autres outil conduit parfois à une pollution de /var/log/syslog, en particulier avec certains messagesqui n'ont aucune incidence.
Il suffit d'éditer la cont 50-default.conf et de mettre, en premières règles les files suivants :
:msg, contains, "error on subcontainer 'ia_addr' insert (-1)" STOP
:msg, contains, "failed to retrieve runc version" STOP
Dans cette exemple, l'erreur de docker sur la "runc version" et celle de snmp sur "ia_addr" seront ignorées.
{kind=link}